
Using pandas with modelx#
pandas is a popular Python package for data manipulation and analysis. It offers versatile data structures, such as DataFrame and Series to store tabular and vector data.
Saving pandas objects in Excel or CSV files#
By default, modelx treats pandas objects in the same way as it treats any other pickleable data, which means that they are pickled and saved with other objects in a binary data file.
In addition to this default behaviour, modelx implements a feature to change this default behaviour for pandas DataFrames and Series, and save them in Excel and CSV files.
Note
This feature require the OpenPyXL package in addition to pandas.
If not yet installed, install OpenPyXL by
pip install openpyxl or conda install openpyxl.
Let’s see how this works.
The script below creates a sample DataFrame df:
>>> import pandas as pd
>>> index = pd.date_range("20210101", periods=3)
>>> df = pd.DataFrame(np.random.randn(3, 3), index=index, columns=list("XYZ"))
>>> df
X Y Z
2021-01-01 0.184497 0.140037 -1.599499
2021-01-02 -1.029170 0.588080 0.081129
2021-01-03 0.028450 -0.490102 0.025208
Let’s also create a sample model and a sample space in the model,
and assign the space to space:
>>> import modelx as mx
>>> model = mx.new_model() # Creates a new model Model1
>>> space = model.new_space() # Creates a new space Space1
To assign the sample DataFrame to x in the space,
we would normally do:
>>> space.x = df
By saving the model, df would be stored in a binary file named data.pickle
under the _data directory in the model directory.
To save the DataFrame in an Excel file, instead of the assignment above,
new_pandas() should be used like this:
>>> space.new_pandas("x", "Space1/df.xlsx", data=df, file_type="excel", sheet="df1")
The code above not only assigns df to x in space,
but also associates metadata to df for saving it in an Excel file,
such as file path, file type and sheet name.
The code below saves the model to a folder named model in the current directory:
>>> model.write("model")
We should find an Excel file named df.xlsx in the model/Space1 directory.
The file contains a table of df on sheet df1.
The metadata is associated to df as PandasData object.
We can check the metadata by calling the model’s get_spec() method:
>>> model.get_spec(df)
<PandasData path='Space1/df.xlsx' file_type='excel' sheet='df1'>
Note that the metadata is associated to df, the DataFrame object,
not to x, because df can be assigned to other names.
We can assign df to, say, y after assigning df to x
by new_pandas().
This time, we don’t need to use new_pandas()
but we can simply use the assignment operation, because
the metadata is already assigned to df:
>>> space.y = df
The diagram illustrates the relationships between x, y, df,
and the PandasData object.
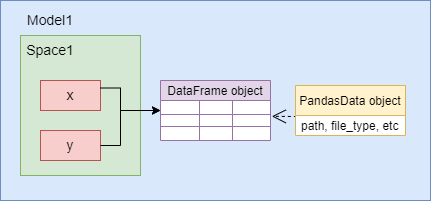
Both x and y refer to the same DataFrame object,
and the PandasData object containing the metadata is
associated to the DataFrame object, not to x or y.
Replacing pandas objects#
Let’s say we want to replace the DataFrame object with a new one,
which is named df2 in the global namespace.
If we simply assign df2 to x:
>>> space.x = df2
Then what happens looks like below:
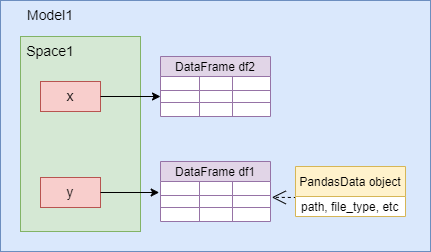
If we subsequently assign df2 to y by:
>>> space.y = df2
Then both x and y refer to df, but
the PandasData object will disappear.
To keep the PandasData and associate it to df2,
we should use update_pandas()
instead of the assignments operations:
>>> model.update_pandas(df, df2)
Then df is replaced with df2, and the PandasData object
is kept and associated to df2:
>>> space.x is df2
True
>>> space.y is df2
True
>>> model.get_spec(df2)
<PandasData path='Space1/df.xlsx' file_type='excel' sheet='df1'>
df2 is now saved to the Excel file by write().
Updating pandas objects#
pandas DataFrames and Series are mutable objects.
We can change their values in place.
modelx cannot detect the change of a mutable object’s value,
so if we change the value of a DataFrame or Series, we need to notify modelx
of the change
by calling update_pandas() to clear cached values
of the cells dependent on the object.
Let’s see how this works by an example:
>>> import modelx as mx
>>> import pandas as pd
>>> model = mx.new_model() # Creates a new model Model1
>>> space = model.new_space() # Creates a new space Space1
>>> df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
>>> df
col1 col2
0 1 3
1 2 4
>>> space.x = df # Use new_pandas instead to save df to a file.
>>> @mx.defcells
... def foo():
... return x['col1'][0]
>>> foo()
1
foo returns and caches a value from df, which is assigned to x.
Now, let’s change the value in df:
>>> df['col1'][0] = 5
>>> space.x
col1 col2
0 5 3
1 2 4
>>> foo()
1
foo doesn’t reflect the change. We need to call update_pandas()
with df explicitly:
>>> model.update_pandas(df) # Tell modelx df is updated.
>>> foo() # The value is retrieved from x again.
5